










Negli articoli precedenti abbiamo visto come configurare il kernel e i componenti chiave di un sistema operativo (OS) embedded. Questo nuovo articolo si concentra sui componenti hardware di Linux embedded e fornisce idee generali per la creazione di driver da utilizzare durante la fase di sviluppo.
Dopo aver trattato le basi di Linux embedded, tra cui il kernel e l’architettura generica del sistema, è ora il momento di parlare di hardware. Discuteremo i numerosi componenti hardware coinvolti, come i bus, l’I/O e i sistemi di rete, oltre ai progetti dei processori. Questo ci permetterà di concludere il nostro viaggio con la scrittura dei driver e di affrontare l’aspetto del tempo reale che sappiamo non essere direttamente implementato in Linux embedded. Alla fine di questo percorso, saremo in grado di gettare le basi per una distribuzione Linux embedded completa.
Lo scopo della seguente analisi non è quello di valutare i vantaggi e gli svantaggi di un componente hardware, ma piuttosto di servire come punto di partenza per la ricerca e l’identificazione dei componenti da includere in un protocollo di un sistema Linux embedded completo che comprenda sia i componenti software che quelli hardware. I sistemi embedded di solito hanno una serie di dispositivi per l’interazione con l’utente, come touchscreen, tastiere, sensori, interfacce RS232, USB e così via. Il controllo completo è assicurato dai controlli del kernel e delle numerose applicazioni utente, nonché dai componenti driver delle periferiche. Ad esempio, i pannelli tattili sono uno dei dispositivi di base per l’interazione con l’utente nei dispositivi embedded, la cui funzionalità principale consiste nell’identificare le coordinate del tocco, il che avviene comunemente generando un interrupt ogni volta che viene effettuato un semplice tocco sul pannello.
Il ruolo del driver del dispositivo, quindi, è quello di interrogare il controller del touchscreen ogni volta che si verifica un interrupt e chiedere al controller di inviare le coordinate del tocco. Quando il sistema riceve le coordinate, invia il tocco e la disponibilità di tutti i dati alle applicazioni. L’applicazione utente elaborerà successivamente i dati in base alle proprie esigenze. In termini di hardware da implementare, gli sviluppatori di software embedded hanno a che fare con dispositivi che di solito non si trovano nei computer tradizionali. Moduli GSM, SPI, I2C, ADC, memoria NAND, radio, GPS e altri dispositivi ne sono un esempio.
In Linux esistono tre tipi di dispositivi: dispositivi di rete, dispositivi a blocchi e dispositivi a caratteri. La maggior parte dei dispositivi rientra nella categoria dei dispositivi a caratteri. Tuttavia, molti driver di dispositivi non sono più implementati direttamente come dispositivi a caratteri. Sono sviluppati in un singolo framework specifico per un particolare dispositivo. Ne sono un esempio il framebuffer (grafica), il V4L2 (acquisizione video) e l’I/O industriale.
Il processore
Linux funziona su un numero sempre crescente di architetture, ma non tutte sono utilizzate nelle configurazioni embedded. Una rapida occhiata alla sottodirectory arch dei sorgenti del kernel Linux mostra che ci sono più di 20 architetture supportate nel kernel ufficiale, mentre le altre sono mantenute dagli sviluppatori in alberi di sviluppo separati. ARM, AVR32, Intel x86, M32R, MIPS, Motorola 68000, PowerPC e Super-H sono alcune delle architetture utilizzate in Linux embedded.
ARM è una famiglia di CPU che viene mantenuta e promossa da ARM Holdings Ltd. A differenza di altri produttori di chip come IBM, Freescale e Intel, ARM Holdings non produce i propri processori. Al contrario, crea interi core di CPU per i propri clienti, addebitando i costi di licenza e consentendo all’azienda di costruire i chip come meglio crede. Tutti i processori ARM condividono lo stesso set di istruzioni ARM che rendono tutte le varianti di una particolare revisione delle istruzioni ARM completamente compatibili.
Ciò non significa che tutte le CPU e le schede ARM possano essere programmate e configurate allo stesso modo. Il linguaggio assembly e i codici binari sono identici per tutti i processori ARM che soddisfano una determinata revisione architetturale. Le attuali revisioni architetturali includono ARMv4T (in cui è stato introdotto il set di istruzioni Thumb), ARMv5TE (la base per i componenti “Xscale”), ARMv6 (dispositivi TI-OMAP di Nokia e ARMv6KZ basato sull’iPhone di Apple) e ARMv7. Ognuna di queste revisioni architettoniche migliora le caratteristiche di una famiglia. Ad esempio, ARMv4T ha introdotto una versione condensata del set di istruzioni che mira a utilizzare meno memoria mantenendo un livello adeguato di prestazioni. Esistono anche processori ARM con prestazioni DSP migliorate (“E”), supporto Java bytecode (“J”), virtualizzazione e un numero crescente di altre opzioni.
Attualmente le CPU ARM sono prodotte da Toshiba, Samsung e molti altri. L’architettura ARM è molto popolare in vari campi di applicazione, dai telefoni cellulari e PDA alle apparecchiature di rete, con centinaia di fornitori di prodotti e servizi che la utilizzano.
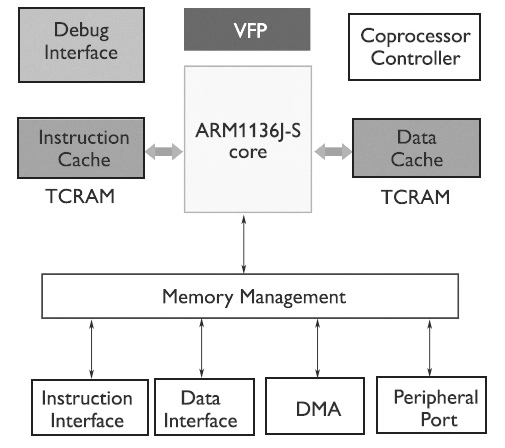
Linux supporta oltre 50 diverse CPU ARM (Figura 1) e un totale di circa 1.900 tipi di macchine diverse. Data la quantità e la varietà di informazioni coinvolte, nonché il ritmo di sviluppo di ARM Linux, si rimanda all’elenco completo e aggiornato dei sistemi ARM supportati e ai relativi dettagli. La famiglia di processori ARM offre un’ampia gamma di opzioni di prezzo e prestazioni con un consumo energetico e un ingombro specifici che la rendono leader nelle rispettive applicazioni. La popolarità dell’architettura ARM è dovuta, in parte, al fatto che offre ai progettisti di sistemi una selezione impareggiabile di strumenti di sviluppo e un’ampia gamma di alternative applicative. La flessibilità e la libertà che i progettisti ottengono da ARM e dai suoi partner semiconduttori sono accompagnate da un obbligo formidabile: Il team di progettazione a livello di sistema deve scegliere il sistema operativo più adatto all’applicazione di destinazione. Esistono tuttavia alcune decisioni di livello superiore che forniscono un quadro di riferimento per la scelta del sistema operativo. Queste includono le risposte a domande semplici, come ad esempio se l’applicazione richiede un’unità di gestione della memoria. Altri aspetti della scelta di un sistema operativo riguardano questioni quali il costo, i tempi di commercializzazione e le caratteristiche speciali, come le funzionalità in tempo reale. La familiarità che il team di progettazione a livello di sistema ha con un particolare sistema operativo è uno dei requisiti più importanti. Lavorando con un sistema operativo familiare, i team di progettazione saranno in grado di ridurre i tempi del ciclo di progettazione per produrre un sistema più performante. In queste condizioni, la domanda principale è quella di valutare una versione del sistema operativo che funzioni su piattaforme ARM. Se l’applicazione è nuova o se è stata presa la decisione di passare a un nuovo sistema operativo, è necessario considerare alcuni fattori, quali:
- Costo totale (include i costi diretti, come licenze, formazione, supporto e royalties)
Capacità in tempo reale - Disponibilità e prestazioni del software (la facilità d’uso e la capacità di fornire un sistema ad alte prestazioni sono ovviamente i criteri chiave per la valutazione di un sistema operativo)
Compatibilità hardware/CPU (il problema della compatibilità si riduce notevolmente quando si utilizza un processore ARM, perché la leadership di mercato di ARM è un incentivo per gli altri produttori di hardware a progettare la compatibilità nei loro prodotti) - Dimensione del codice di utilizzo/memoria
- Capacità di rete
- Documentazione e supporto tecnico
- Reputazione del fornitore
- Costi di progettazione ingegneristica non ricorrenti (comprendono le licenze software, l’assistenza tecnica e gli stipendi pagati a progettisti e programmatori)

Interfaccia bus
I bus e le interfacce sono l’elemento di collegamento tra la CPU e le periferiche del sistema. Ogni bus e interfaccia ha una propria complessità e il livello di supporto di Linux offre diverse opzioni. In particolare, Linux supporta molti bus, alcuni dei quali sono utilizzati soprattutto nelle workstation o nei sistemi server. L’astrazione del sistema Linux consente al kernel di supportare vari dispositivi, che vengono rilevati attraverso l’uso di codice specifico per la piattaforma o possono essere menzionati attraverso il bootloader/kernel. In questa sezione cercheremo di fornire un supporto descrittivo per i principali bus utilizzati nei sistemi Linux embedded.
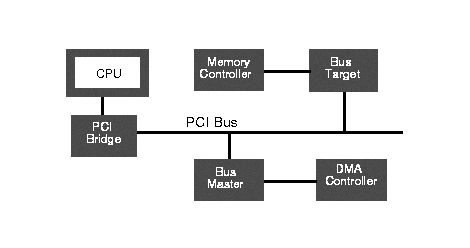
Peripheral Component Interconnect (PCI) è il bus più diffuso attualmente disponibile (Figura 2). Progettato come sostituto del bus ISA dei PC Intel, il PCI è ora disponibile in due forme: la tradizionale forma a slot paralleli con 120 (PCI a 32 bit) o 184 (PCI-X a 64 bit) corsie e la più recente (e potenzialmente molto più veloce) PCI Express (comunemente chiamata PCIe o PCI-E). Il PCI richiede un supporto software per essere utilizzato dai driver dei dispositivi. La prima parte di questo supporto è necessaria per inizializzare e configurare i dispositivi PCI all’avvio (chiamata enumerazione PCI). Nei sistemi PC, questa operazione viene tradizionalmente eseguita dal BIOS e, se il BIOS è stato inizializzato, il kernel recupera le informazioni PCI; tuttavia, il kernel è in grado di inizializzare e configurare i dispositivi. In entrambi i casi, il kernel fornisce un’API per i driver dei dispositivi in modo da poter accedere alle informazioni sui dispositivi sul bus PCI e agire di conseguenza. Esiste anche una serie di strumenti di facile utilizzo per manipolare i dispositivi PCI, come ad esempio gli elenchi lspci, utilizzati per elencare i dispositivi e i bus PCI.
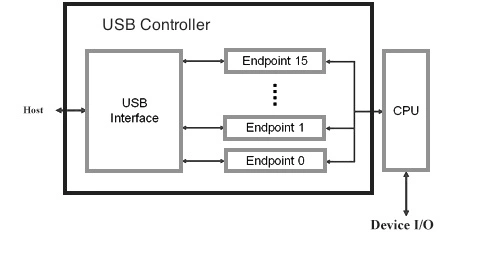
Universal Serial Bus (USB) è stato sviluppato e gestito da un gruppo di aziende che formano l’USB Implementers Forum (USB-IF). Inizialmente sviluppato per sostituire le interfacce di collegamento frammentate, l’USB (Figura 3) si è rapidamente affermato come interfaccia di scelta per le periferiche grazie al suo basso costo, alla facilità d’uso e all’alta velocità di trasmissione. Il bus USB è sempre più presente nell’hardware dei sistemi embedded, come SBC e SoC di vari produttori, soprattutto grazie al potenziamento della periferica con USB On-The-Go (OTG): una specifica che consente a qualsiasi dispositivo host di comunicare con i dispositivi USB. I dispositivi USB sono collegati ad albero. La radice è chiamata hub primario e di solito è la scheda madre a cui sono collegati tutti i dispositivi USB e gli hub non radice. L’hub primario è responsabile di tutti i dispositivi ad esso collegati, direttamente o tramite hub secondari. Il componente principale del supporto USB di Linux è fornito dallo stack USB nel kernel, che comprende anche i driver per i dispositivi USB supportati da Linux. Gli strumenti per la gestione dei dispositivi USB sono disponibili sul sito web del progetto USB Linux.
Infine, un bus particolarmente “vecchio” ancora utilizzato nella gestione dei dispositivi è la porta seriale, che è senza dubbio la migliore amica (o la peggiore nemica, a seconda delle esperienze passate con questa interfaccia) dello sviluppatore di sistemi. Molti sistemi embedded vengono sviluppati e sottoposti a debug utilizzando un collegamento seriale RS232 tra l’host e il target. La semplicità dell’interfaccia RS232 ne ha favorito la diffusione e l’adozione, anche se la sua larghezza di banda è piuttosto limitata rispetto ad altri mezzi di trasmissione. Il driver seriale (UART) principale nel kernel è drivers / char / serial.c. Alcune architetture, come SuperH, hanno altri driver seriali per adattarsi al loro hardware. Tuttavia, i dispositivi seriali in Linux sono uniformemente accessibili come dispositivi terminali, come nei sistemi Unix, indipendentemente dall’hardware sottostante e dai relativi driver. Le voci dei dispositivi corrispondenti iniziano con / dev / ttyS0 e possono arrivare fino a / dev / ttyS191.
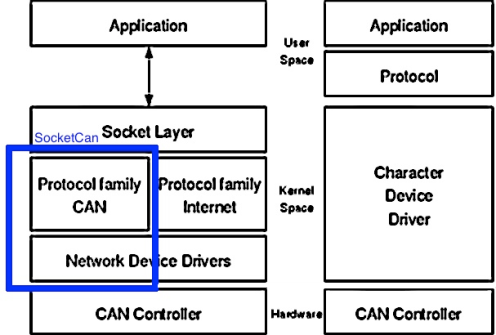
Il bus CAN in dettaglio
Oggi il bus CAN è utilizzato in un’ampia varietà di applicazioni di controllo. È una tecnologia di rete che trova largo impiego nell’automazione, nei dispositivi embedded e nell’automotive, espressamente progettata per funzionare anche in ambienti fortemente disturbati dalla presenza di onde elettromagnetiche e di varie fonti di rumore.
Il CAN trasmette i dati attraverso un protocollo basato su bit “dominanti” e “recessivi”. I frame possono essere suddivisi in quattro tipi: frame di dati, frame remoto, frame di errore e frame di sovraccarico. L’implementazione di un protocollo CAN nei sistemi di controllo deve soddisfare requisiti di temporizzazione rigorosi, fino a pochi millisecondi. Questo non può essere garantito nel contesto dello spazio utente, dove diversi processi di un sistema multitasking condividono la stessa CPU. A seconda del sistema da caricare, i processi ricevono il loro tempo di CPU regolato dallo scheduler e dalla risoluzione del timer di sistema. L’alternativa comune per l’implementazione dei protocolli per i sistemi operativi multitasking è quella di avere una CPU CAN separata o di utilizzare una variante in tempo reale del sistema operativo multitasking selezionato. La comunicazione di rete punto-punto nei sistemi operativi multitasking è ben nota grazie alla comunicazione Internet Protocol (IP). Diversi protocolli basati su IP orientati alla connessione e senza connessione, come TCP e UDP, sono lo stato dell’arte nei comuni sistemi operativi. Personalizzando questa tecnologia di rete Internet per soddisfare gli stessi requisiti dei protocolli di trasporto CAN, si ottiene un’implementazione del bus all’interno dello stack di rete del sistema operativo.Questo approccio presenta diversi vantaggi:
- interfacce di programmazione standard per le chiamate di sistema (“socket di rete”)
- Modello di driver di rete standard
- Livelli di astrazione stabiliti nello stack di rete
- I protocolli di comunicazione sono implementati nel contesto del sistema operativo.
- Accesso multiutente alla rete

Monitoraggio dei sistemi
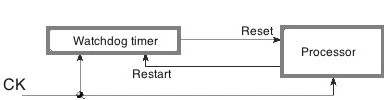
I guasti sono una componente inevitabile dei moderni sistemi embedded, che può essere mitigata da un’attenta progettazione e da test di runtime. Spetta al progettista pianificare questa possibilità e fornire mezzi di recupero monitorando il sistema hardware e software come sistemi di watchdog (Figura 5).
Linux supporta due tipi di strutture di monitoraggio del sistema: i timer di watchdog e il monitoraggio della salute dell’hardware. Per il primo tipo di struttura sono previste implementazioni sia hardware che software, mentre per il monitoraggio della salute dell’hardware, che fornisce informazioni sullo stato fisico del sistema, è sempre necessario un hardware appropriato.
Il kernel Linux include i driver per molti timer watchdog. L’elenco completo dei dispositivi watchdog supportati si trova nel menu di configurazione della compilazione del kernel, nel sottomenu Watchdog Cards. L’elenco comprende i driver per le schede timer watchdog periferiche, un watchdog software e i driver per i timer watchdog presenti in alcune CPU come MachZ e SuperH. Sebbene sia consigliabile utilizzare il watchdog software per evitare il costo di un watchdog hardware adeguato, in alcune circostanze il watchdog software potrebbe non riuscire a riavviare il sistema e la capacità di riavvio dipenderà dallo stato delle macchine e degli interrupt. I timer di watchdog sono visti come / dev / watchdog in Linux e devono essere scritti periodicamente per evitare il riavvio del sistema.
Linux supporta un paio di dispositivi di monitoraggio hardware attraverso “Hardware Monitoring by lm_sensors”. Il sito web del progetto contiene un elenco completo dei dispositivi supportati e un’ampia documentazione sull’installazione e il funzionamento del software. Il pacchetto lm_sensors, disponibile sul sito web del progetto, comprende sia i driver dei dispositivi che le utilità a livello utente. Queste utility includono una serie di opzioni e, in particolare, sensord, un demone in grado di registrare i valori dei sensori e di avvisare il sistema attraverso il livello syslog ALERT quando si verifica una condizione di allarme.
Archiviazione
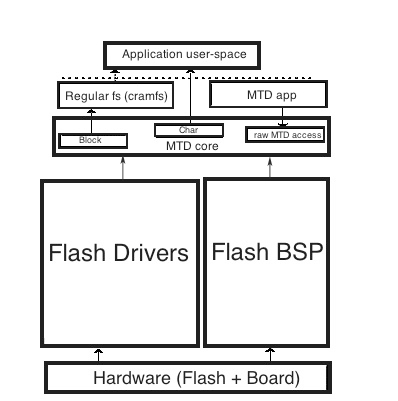
Storicamente, l’archiviazione nei sistemi embedded viene effettuata utilizzando una ROM per il codice di sola lettura e una NVRAM per la memorizzazione dei dati in lettura e scrittura. Tuttavia, oggi sono state sostituite dalla tecnologia flash, che offre un’alta densità combinata con un basso costo, che ne ha aumentato notevolmente l’uso nei sistemi embedded. In un sistema Linux embedded, la flash viene generalmente utilizzata per memorizzare il boot loader e l’immagine del sistema operativo, le applicazioni, le immagini di libreria e i file di lettura-scrittura (con i dati di configurazione). Di questi quattro, i primi tre sono di sola lettura per la maggior parte del tempo di esecuzione del sistema. Se si utilizza un boot loader, si dovrebbero avere almeno due partizioni: una con il boot loader e l’altra con il file system principale. La suddivisione della flash può essere descritta come una mappa della flash, cioè una mappa di memoria fissa che indica come si intende partizionare la flash per la memorizzazione dei dati. Il sottosistema del kernel MTD mostrato nella Figura 6 fornisce il supporto per la memoria flash e per memorie a stato solido non volatili simili. Il sottosistema MTD è stato creato per fornire un livello di astrazione tra i driver dei dispositivi e le applicazioni di livello superiore. È composto dai seguenti elementi: il nucleo MTD, che include un’infrastruttura di librerie di routine e strutture di dati utilizzate dal resto del sottosistema; i driver di mappa che analizzano ciò che il processore deve eseguire quando riceve richieste di accesso; i driver NOR che conoscono i comandi necessari per parlare con la flash NOR; i driver NAND che implementano il supporto di basso livello per i controller della flash NAND; i moduli utente, il livello che interagisce con i programmi dello spazio utente; e i singoli driver di dispositivo per alcune flash speciali.

Driver embedded
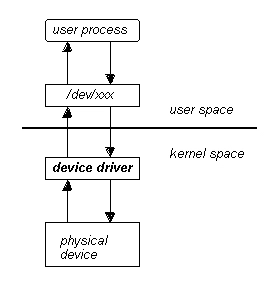
I driver di periferica (Figura 7) fanno parte di Linux e forniscono accesso all’hardware con l’aiuto di un’interfaccia ben definita. I driver di dispositivo sono classificati in tre tipi:
Caratteri, utilizzati per pilotare dispositivi ad accesso sequenziale accessibili dall’applicazione utilizzando chiamate standard come open, read. Ad esempio, la console di testo (/ dev / console) e le porte seriali (/ dev / ttyS0) sono esempi di driver a caratteri.
Block, utilizzati per pilotare dispositivi ad accesso casuale attraverso lo scambio di dati a livello di blocco. I driver di periferica, a differenza dei driver di font, sono utilizzati per memorizzare i file system e le loro applicazioni non sono accessibili direttamente ma solo attraverso un file system. Ad esempio, un driver di disco è un driver di dispositivo a blocchi. Le reti sono trattate come una classe distinta di driver di dispositivo perché interagiscono con lo stack del protocollo di rete. Il kernel offre diverse subroutine o funzioni dello spazio utente che consentono al programmatore di eseguire applicazioni per l’utente finale per interagire con l’hardware. Questo dialogo avviene solitamente nei sistemi UNIX o Linux, attraverso funzioni o subroutine per la lettura e la scrittura di file. D’altra parte, il kernel Linux offre diverse funzioni o subroutine per eseguire interazioni di basso livello direttamente con l’hardware e consentire il trasferimento di informazioni dal kernel allo spazio utente. Di solito, per ogni funzione nello spazio utente (che consente l’uso di dispositivi o file), esiste un equivalente nello spazio kernel (che consente il trasferimento di informazioni dal kernel all’utente e viceversa). Nel kernel Linux sono presenti molti driver di periferica (uno dei punti di forza di Linux), che possono essere convenientemente distinti, in particolare: il codice del kernel, che fa parte del kernel stesso e, se mal progettato, può danneggiare l’intero sistema; le interfacce del kernel che forniscono un’interfaccia standard al kernel Linux o al sottosistema appropriato; i meccanismi e i servizi del kernel che fanno uso di servizi standard come l’allocazione della memoria e gli interrupt. La maggior parte dei driver di periferica di Linux possono essere caricati su richiesta come moduli del kernel quando sono necessari e scaricati quando non sono più utilizzati; questo rende il kernel molto adattabile ed efficiente con le risorse del sistema.
I driver del kernel Linux possono essere compilati come moduli che possono essere caricati in fase di esecuzione o integrati nel kernel stesso. I driver modulo sono noti come moduli caricabili del kernel (LKM) e si comportano in modo simile alle DLL di Windows. Un LKM è costituito da un singolo file oggetto ELF, solitamente denominato “serial.ko”. Un vantaggio significativo è che può essere caricato in memoria durante l’esecuzione con un semplice comando; inoltre, quando si aggiorna il codice LKM, non è necessario compilare l’intero kernel, ma solo l’LKM.
Leggi l’articolo originale su https://www.eeweb.com/embedded-linux-design-hardware-and-drivers/
Notizie sull’autore: Maurizio Di Paolo Emilio, Author at EEWeb




